


- Published on
Some freshness with Linux security modules and ebpf
- Authors

- Name
- Luca Montechiesi
- lumontec
One of the shiny new features available in the linux kernel since this patch on version 5.7 is the capability to attach ebpf programs directly to linux security module hooks in order to implement flexible authorization policies that can be injected in-kernel exploiting bpf magic. This opens up a whole class of fresh solutions that I want to geolocate inside of the rich landscape of kernel security
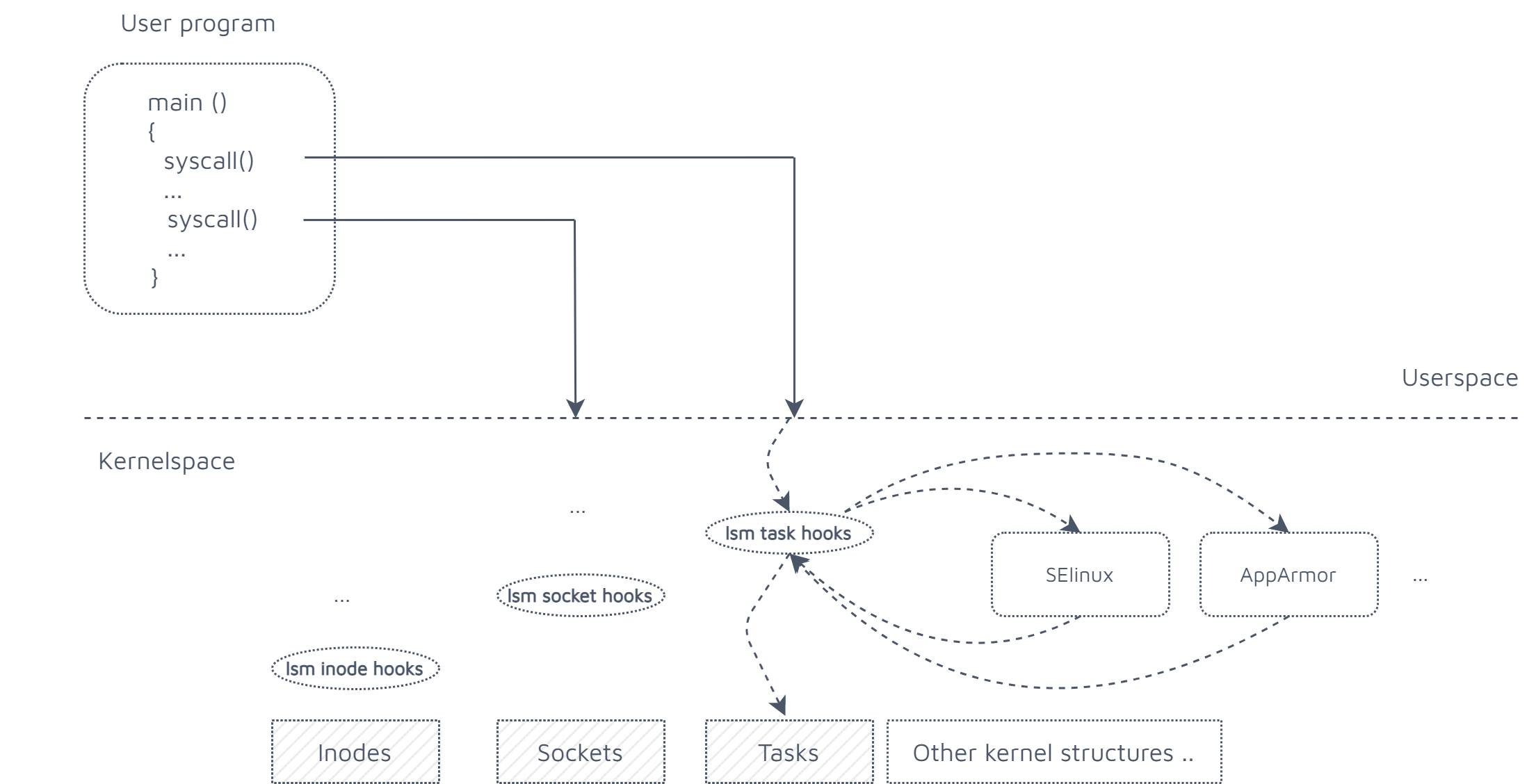
Linux security modules framework
Linux is a constantly evolving incredibly widespread operating system, and it should be pretty straightforward to understand that for these two reasons alone providing strong guarantees about security is a really complex matter. The faster the technology evolves the more fixes are needed and faster deployment of those will be required. Those are the two main reasons that drove kernel developers to design an extremely low level framework exposing a number of hooks which are capable of authorizing or rejecting specific operations happening against sensible kernel resources.
The architecture of linux security modules is based on 3 main concepts:
- Locality: Hooks are invoked as close as possible to the resource being protected to deter against TOCTOU exploits
- Single reposnibility: Hooks offer protection for very specific classes of operations
- Agnostic: Hooks are simple function declarations that security engineers use to define their own implementation of security modules
That third point in particular is quite important because it frees the linux kernel from any sort of specific security model implementation allowing third party developers to implement their own frameworks as well as to easily replace / fix them in case vulnerabilities emerge in their codebase. Quite famous examples of these implementations are Apparmor and SELinux which (at the time of this post) is the default security module enabled on every single android device available on the market btw.
eBPF and libbpf
Bpf is a quite old technology born with its roots in the packet capture field (close to tcpdump) but just recently extended to provide developers with the capability to inject custom code inside the linux kernel without any need to recompile the kernel itself. These bpf programs can be attached to specific kernel facilities like tracepoints or kprobes and can be flexibly deployed to implement powerful tracing and kernel observability tools. Bcc and bpftrace are two examples of tools that leverage extended bpf to provide the user with insightful metrics at a minimal performance costs.
And that's almost awasome..
I mean it is awasome, but writing bpf programs is not really that easy for a number of reasons, consider that our code gets injected in the kernel thus has to be verified of beeing free of circular dependencies or infinite loops or unsafe access to memory .. Everything that could panic or halt your os (and sometimes even straight correct code) is rejected by one mythological kernel routine called the bpf verifier that is pickier than your girlfriend in the wrong day. But that is not all.
The linux kernel is constantly evolving by changing and moving its internal structures as versions change, then how do I write code that is actually portable between these ?
Libbpf is a library that aims to simplify the deployment of bpf programs by offering a number of helper functions useful to access internal kernel information providing a stable view of these structures. A functionalty called CO-RE (compile once run everywhere) magically hides from user a quantity of pointer chasing and field relocation logic, allowing us to happily access with some limitations a stable view of kernel information across different machines.
eBPF + LSM = KRSI freshness
Linux kernel v5.7 included a really interesting patch, that allows security people to design custom policies which can be injected in-kernel to be triggered by the security hooks exposed by the LSM framework. KRSI stands for Kernel Runtime Security Instrumentation and the target of this patch is to allow users to implement lsm hooks by utilizing bpf compiled code. This gets interesting for a couple of reasons:
- Kernel function call flow mutation: AFAIK this is the very first application of ebpf where injected code is actually capable reject / blocking the execution of some kernel logic
- Flexibility: ebpf can be attached / removed on the fly offering fast replacement of vulerable security code
This is a quite huge advancement that hasn't come without strong debate about performance and critycism with the main point being the following:
Lsm hooks are not an api: this is actually a problem that follows the power of ebpf, due to the fact that it can basically consume information from everywhere in the kernel, it ends up using anything as as api, and api need to be stable. That is basically the reason why tracepoints are widely more used to attach bpf programs with respect to kprobes. So the real question is, how stable are lsm hooks ? Quite stable as I understood, but is also true that we are talking about kernel security here so total stability would probably be required in order to reliably build something trustable. Time will tell..
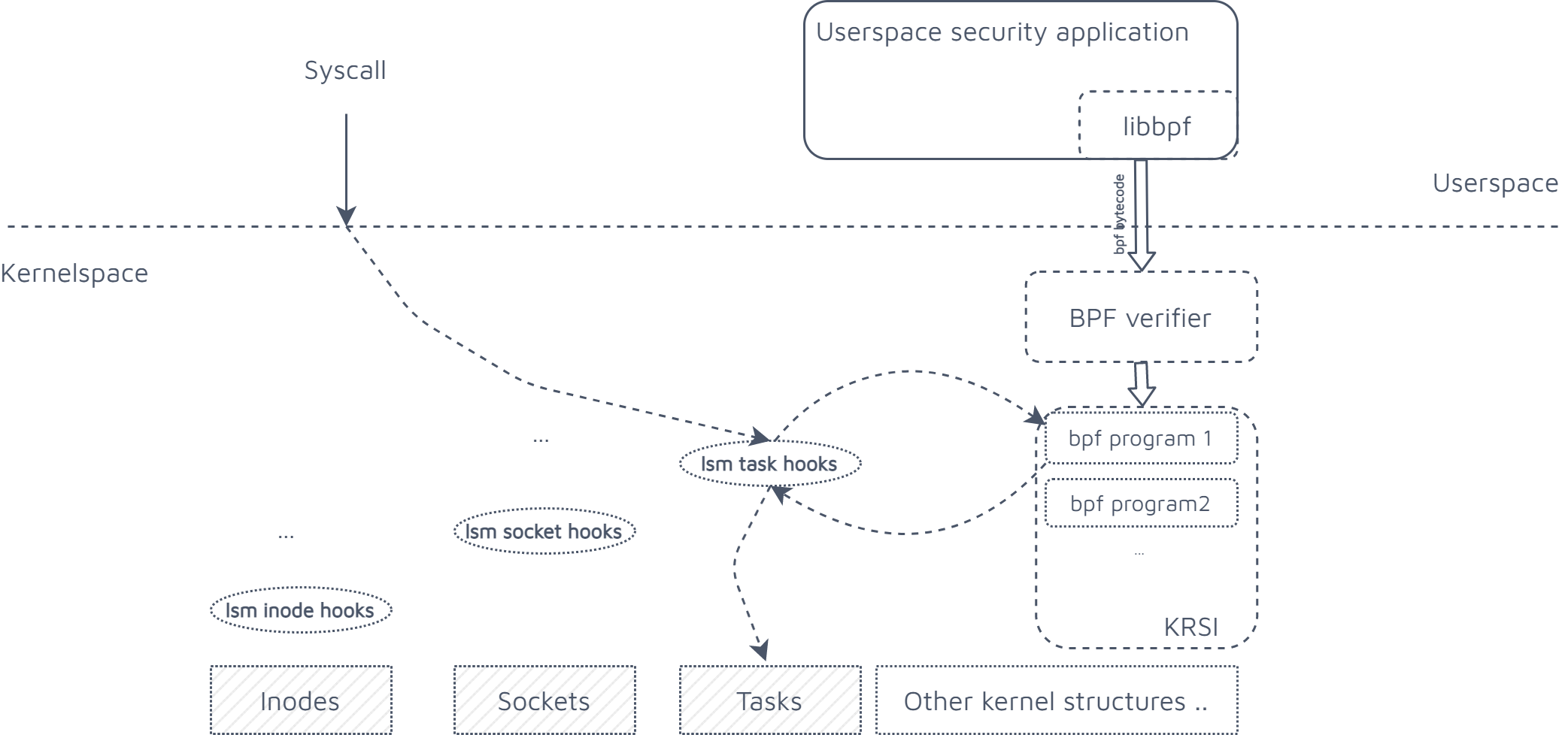
KRSI and other fantastic beasts
Ok so in this final section I want to provide a high level view of the linux kernel and MAC solutions and help you and myself out in understanding where krsi is sitting and what it can replace/improve in this rich landscape.
Syscalls and Kernel resources
In laughably simple model we have userspace applications interacting with kernel resources by means of syscalls, which is really the stable api seen by users and the only possible way that they have to access and claim their share of os resources. Right in front of these we have the lsm hooks enforcing protection logic.
Userspace vs kernelspace enforcement
There is a whole family of tools that implement security enforcement by restricting syscalls, which makes a whole lot of sense at first sight:
If users trigger syscalls to interact with kernel state why not restricting those actions directly ?
This is exactly what tools like seccomp or systrace do in the first place. Seccomp (which stands for secure computing) is a kernel facility that enables a process to auto restrict its access to syscalls, and was extended to support bpf injection in what is currently known as seccomp-bpf.
With seccomp-bpf is possible to attach bpf programs to syscalls in order to reject or pass them (quite similar to krsi right ?) which is awasome, moreover it is nicely wrapped by libseccomp library, the same library extesively used by runc in order to allow enforcement for its open-container-initiative runtime security. If you are asking yourself, yes, this is the mainmechanism behind those container security profiles that implement syscall access restriction both in docker and kubernetes environments.
So what's the problem with this approach ?
The problem is that enforcement is performed very far from the kernel resources being protected, and relying on userspace data (e.g. paths or strings passed syscall arguments) exposes us to a whole family of subtle security exploits where this information can be manipulated after the checks have been done by exploiting race conditions (I won't enter those details here).
So maybe you are asking yourselves:
Then what kind of information can I use inside my seccomp-bpf code ?
And the answer is: everything which is not passed as a pointer argument to syscalls. Thus formulating complex policies with seccomp-bpf is virtually impossible, as I cannot have access to very basic information such as:
- the name of the executable
- some path i am passing to my syscall
Add to that the fact that syscalls are contantly evolving, now you should have a quite clear idea on why lsm hooks were introduced.
They offered the capabilty to implement very sophisticated security policies deep inside the linux kernel. The only problem being that every time a fix was required, a whole kernel recompilation was required. This rigidity concerning deployment is the main reason why security modules such as SELinux and AppArmor ended up being include straight in the kernel tree, event thought this wasn't likely the idea when LSM framework was conceived.
BUT this is not the case anymore with krsi, that makes the whole developement/deployment cycle far easier to implement without even restarting the machine.
Requirements
Ok, but tell me what I need to play with this stuff
You need a linux kernel > 5.7 compiled with the following options:
- BPF_SYSCALL
- DEBUG_INFO
- DEBUG_INFO_BTF
- BPF_LSM
Being an extremely fresh feature, no os that I know of ships with option BPF_LSM enabled by default, yet all these will likely be enabled in the future. Ubuntu upstream kernel for example already includes in its version 5.10.0 the first three options and is likely to enable the last one quite soon.
Wrapping the spring roll
Writing an deployng flexible security code has never been so easy, I expect to see a number of different solutions grow building their foundation on KRSI and bpf.
Deep lsm observability will likely become another quite crucial aspect both when deveoloping and deploying these kind of programs. That is exatcly why I wrote a simple security tracing utility to provide an high level view of what a specific process is doing at the hooks level.
That is juice for my next post.
Want to talk about this post? Discuss this on Medium →